Dataset search results should always show a snippet
12679
Reporter: lfrancke
Assignee: mdoering
Type: Improvement
Summary: Dataset search results should always show a snippet
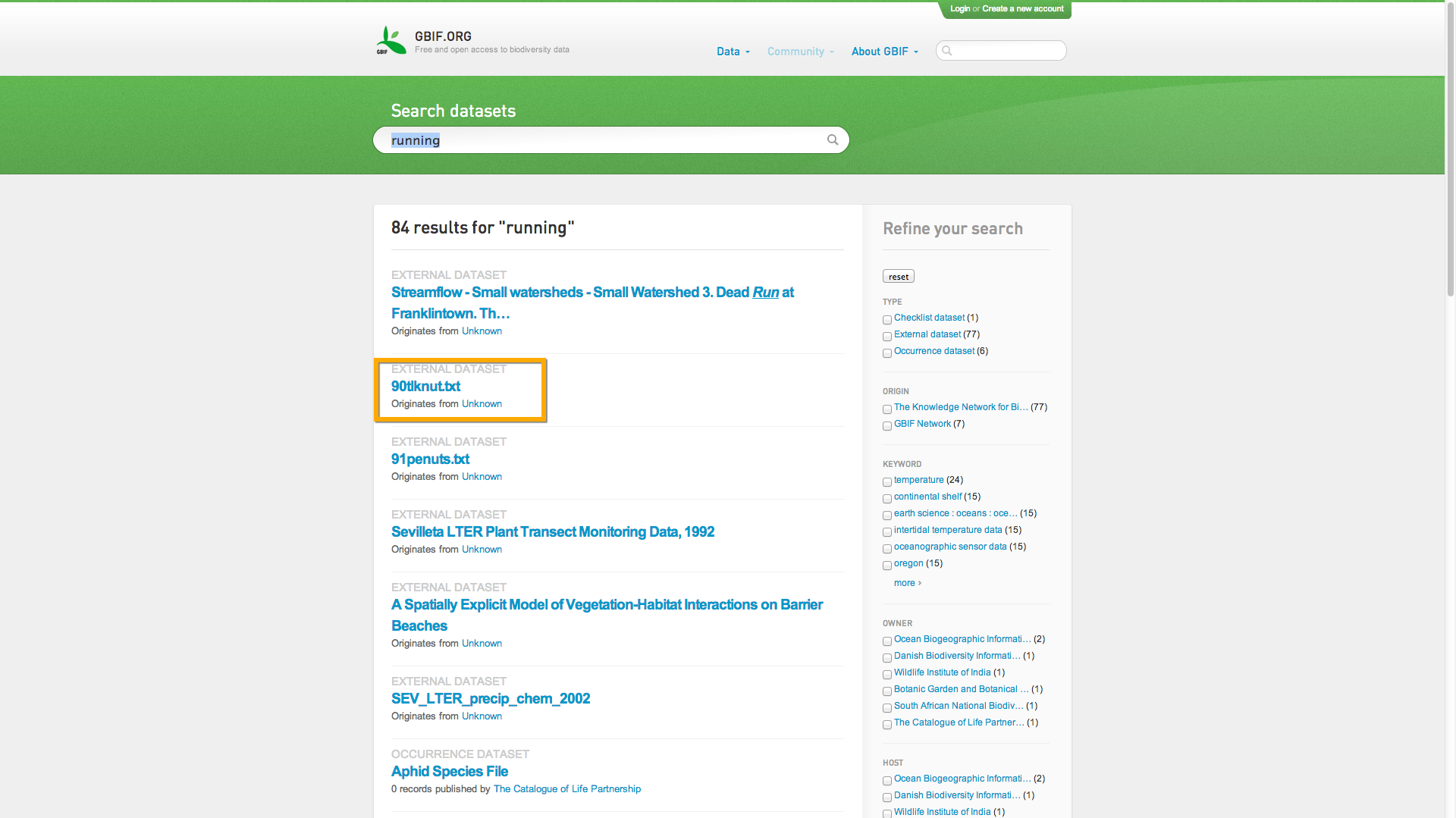
Description: It's confusing to not know why a result is a result. Like in the screenshot I'd like to see a snippet of the Description or anything to tell me why the result is included.
Priority: Major
Resolution: Fixed
Status: Closed
Created: 2013-01-29 17:38:28.417
Updated: 2016-06-22 11:47:44.936
Resolved: 2013-02-18 16:56:26.636
Author: kbraak@gbif.org
Created: 2013-01-31 18:15:25.293
Updated: 2013-02-01 00:57:47.082
Often a match happens against only the full_text field. The full_text field is basically the external (XML) metadata document.
On the results page, we don't want to show highlighted matches within XML. Furthermore, in order to show highlighted matches in the full_text field, we would have to store it, and storing the full_text field increases the size of the solr index substantially.
See the attached screenshot showing one way that we could show the user that their search matched the external metadata document. Basically I think we can still do this without storing the full_text field - if the match didn't happen in any of the stored fields, it must have matched the full_text field, right?
Also for this issue, I have also had to display some missing fields such as keywords and description in the search results page.
Please note, this change to the template/action isn't committed yet. [~fmendez@gbif.org] what do you think.
Author: kbraak@gbif.org
Created: 2013-02-01 18:36:24.783
Updated: 2013-02-01 18:36:24.783
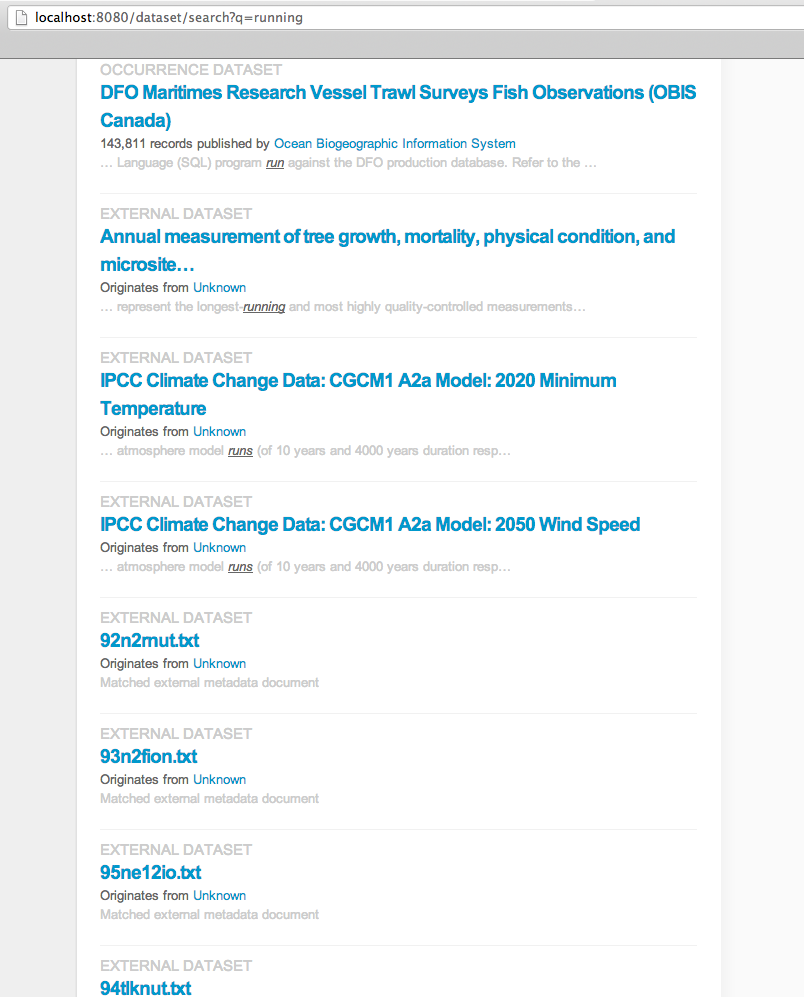
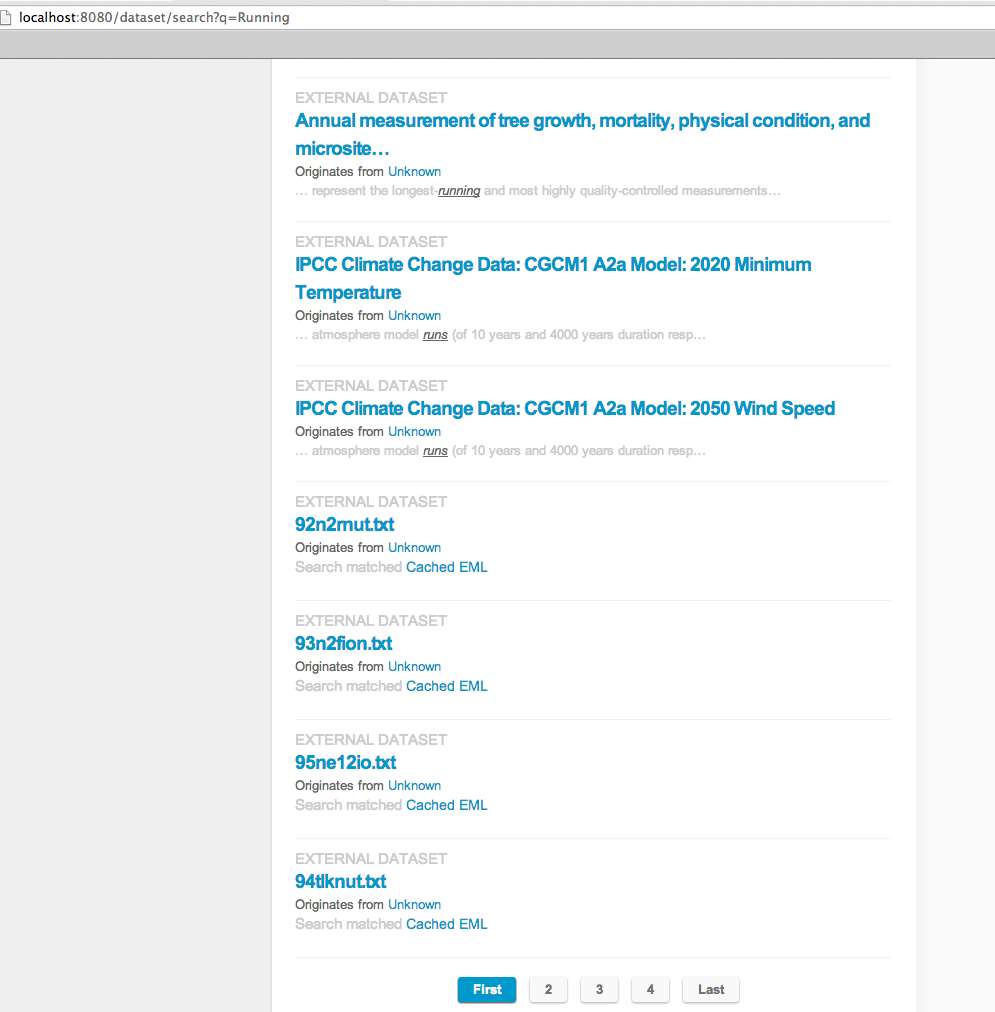
New screenshot shows revised full_text only match, with link to cached metadata document.
Change committed in changeset 1342.
Author: mdoering@gbif.org
Comment: Good idea. Seeing the "running" query is it a good idea to use stemming in our search? It will only work for english and Im not sure if anyone expects that anyways. Im considering to turn that off
Created: 2013-02-04 15:32:36.682
Updated: 2013-02-04 15:32:36.682
Author: kbraak@gbif.org
Created: 2013-02-04 16:40:43.368
Updated: 2013-02-04 16:40:43.368
[~fmendez@gbif.org] and I discussed this briefly last week but came to no conclusion.
It is definitely elevating the number of search hits, particularly against the dataset's full_text field.
It might only be configured for English right now, but that's the language of the majority of our metadata too.
I would at the very least like to retain stemming for plurals (e.g. plants -> plant).
My vote is to keep it for the time being.
Author: kbraak@gbif.org
Created: 2013-02-06 19:46:23.083
Updated: 2013-02-06 19:46:23.083
There is one outstanding problem related to highlighting.
Take a look at http://staging.gbif.org:8080/portal/dataset/search?q=Pon
There is no highlighting for Dataset with title "VFD-RP: Taunus: Ponykoppel Thurner" even though "Pon" should be highighted.
If you run:
http://boma.gbif.org:8080/registry-solr/select?q=%28dataset_title%3Apon%5E20.0+OR+dataset_title_ngram%3Apon%5E12.0+OR+dataset_title_nedge%3Apon%5E10.0+OR+keyword%3Apon%5E4.0+OR+iso_country_code%3Apon%5E3.0+OR+owning_organization_title%3Apon%5E2.0+OR+hosting_organization_title%3Apon%5E2.0+OR+description%3Apon%5E1.0+OR+full_text%3Apon%5E0.5%29&rows=20&start=0&q.alt=*%3A*&hl=true&hl.snippets=10&hl.fragsize=0&hl.fl=dataset_title&hl.fl=dataset_title_ngram&hl.fl=dataset_title_nedge&hl.fl=keyword&hl.fl=iso_country_code&hl.fl=owning_organization_title&hl.fl=hosting_organization_title&hl.fl=description&hl.fl=full_text&sort=score+desc%2Cdataset_title+asc&facet=true&facet.mincount=1&facet.missing=true&facet.sort=count&facet.field=%7B%21ex%3Dffqiso_country_code%7Diso_country_code&facet.field=%7B%21ex%3Dffqhosting_organization_key%7Dhosting_organization_key&facet.field=%7B%21ex%3Dffqdecade%7Ddecade&facet.field=%7B%21ex%3Dffqdataset_subtype%7Ddataset_subtype&facet.field=%7B%21ex%3Dffqowning_organization_key%7Downing_organization_key&facet.field=%7B%21ex%3Dffqkeyword%7Dkeyword&facet.field=%7B%21ex%3Dffqnetwork_of_origin_key%7Dnetwork_of_origin_key&facet.field=%7B%21ex%3Dffqdataset_type%7Ddataset_type&f.iso_country_code.facet.missing=false&f.iso_country_code.facet.sort=index&f.hosting_organization_key.facet.missing=false&f.decade.facet.missing=false&f.decade.facet.sort=index&f.dataset_subtype.facet.missing=false&f.dataset_subtype.facet.sort=index&f.owning_organization_key.facet.missing=false&f.keyword.facet.missing=false&f.network_of_origin_key.facet.missing=false&f.network_of_origin_key.facet.sort=index&f.dataset_type.facet.missing=false&f.dataset_type.facet.sort=index
you will notice in the list at the bottom:
VFD-RP: Taunus: Ponykoppel Thurner
There is no highlighting!
So far I can't figure out how something can appear in the highlighted list with no highlighting tags. A simple solution would be to highlight inside the template when rendering the search list. What do you think [~mdoering@gbif.org] and [~fmendez@gbif.org]
Author: fmendez@gbif.org
Created: 2013-02-07 09:28:11.122
Updated: 2013-02-07 09:28:11.122
Yes, kyle the solution that you described is, probably, out only option; Solr supports highlighting for fixed ngrams fields, a fixed ngram is field with minGramSize = maxGramSize; and that's not our case:
Author: mdoering@gbif.org
Created: 2013-02-07 10:43:16.782
Updated: 2013-02-07 10:43:16.782
To avoid the nasty checks in the portal if a search originally has matched the full text field I would also suggest to add a boolean field for that to the search result object and populate that directly when converting from the solr object. The respective highlighting section of the solr response is simply empty in that case and it should be simple to detect within our service: