Author: trobertson@gbif.org
Created: 2012-07-10 09:33:22.701
Updated: 2012-07-10 13:14:08.525
One example where this has been noticed:
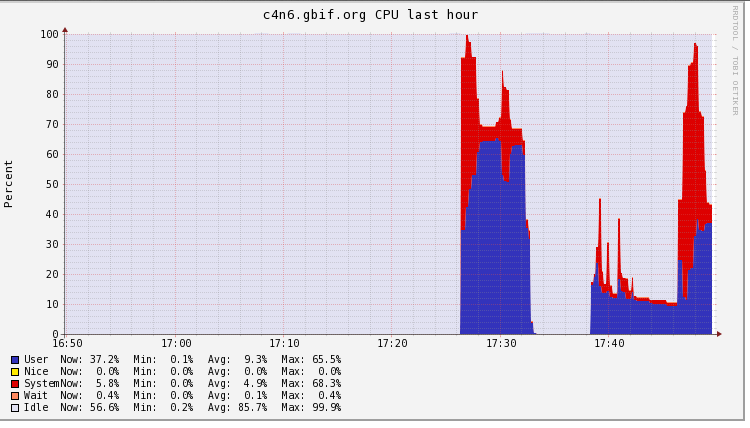
Running a scan using hive (on a table that was not majorly compacted) showed a very strange region server request count [1] where you see long periods where the regions are not getting high requests. This seems to correlate the periods the machines having high cpu (up to 95% on some machines) [2]
This may be caused by the compaction, but might be indicative of something else. It seems unusual the system CPU is so high, and region requests are down at 100s-1000s when should be all pegged up near 500k.
[1] http://dev.gbif.org/ganglia/graph.php?cs=07%2F09%2F2012+20%3A47+&ce=07%2F09%2F2012+21%3A00+&&r=hour&z=xlarge&title=hbase.regionserver.requests&mreg%5B%5D=%5Ehbase.regionserver.requests%24&hreg%5B%5D=c4&aggregate=1&hl=c4n1.gbif.org%7Chadoop-3%2Cc4n2.gbif.org%7Chadoop-3%2Cc4n3.gbif.org%7Chadoop-3%2Cc4n4.gbif.org%7Chadoop-3%2Cc4n5.gbif.org%7Chadoop-3%2Cc4n6.gbif.org%7Chadoop-3
[2] http://dev.gbif.org/ganglia/graph.php?cs=07%2F09%2F2012+20%3A47+&ce=07%2F09%2F2012+21%3A00+&r=hour&z=xlarge&title=cpu_system&mreg%5B%5D=%5Ecpu_system%24&hreg%5B%5D=c4&aggregate=1&hl=c4n1.gbif.org%7Chadoop-3%2Cc4n2.gbif.org%7Chadoop-3%2Cc4n3.gbif.org%7Chadoop-3%2Cc4n4.gbif.org%7Chadoop-3%2Cc4n5.gbif.org%7Chadoop-3%2Cc4n6.gbif.org%7Chadoop-3
Author: trobertson@gbif.org
Created: 2012-07-11 17:53:32.706
Updated: 2012-07-11 17:53:32.706
Pretty much every scan job exhibits this symptom. Attached are 3 running variations on "select count(*) from uat_occurrence"
Given it is a known issue, any reason we shouldn't apply it now, to eliminate it as a possible cause of sluggish performance?
Author: omeyn@gbif.org
Created: 2012-07-13 09:34:20.829
Updated: 2012-07-13 09:34:20.829
Added this block to the end of rc.local on all c4 machines (and also ran it by hand on the running instance):
# for hadoop, as per https://bugzilla.redhat.com/show_bug.cgi?id=764964
# and https://ccp.cloudera.com/display/CDH4DOC/Known+Issues+and+Work+Arounds+in+CDH4#KnownIssuesandWorkAroundsinCDH4-RedHatLinux%28RHEL6.2and6.3%29
echo no > /sys/kernel/mm/redhat_transparent_hugepage/khugepaged/defrag
echo never >/sys/kernel/mm/redhat_transparent_hugepage/defrag