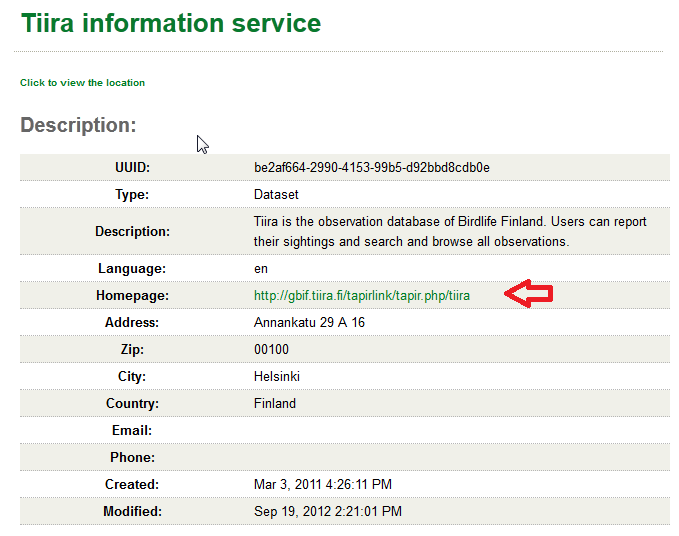
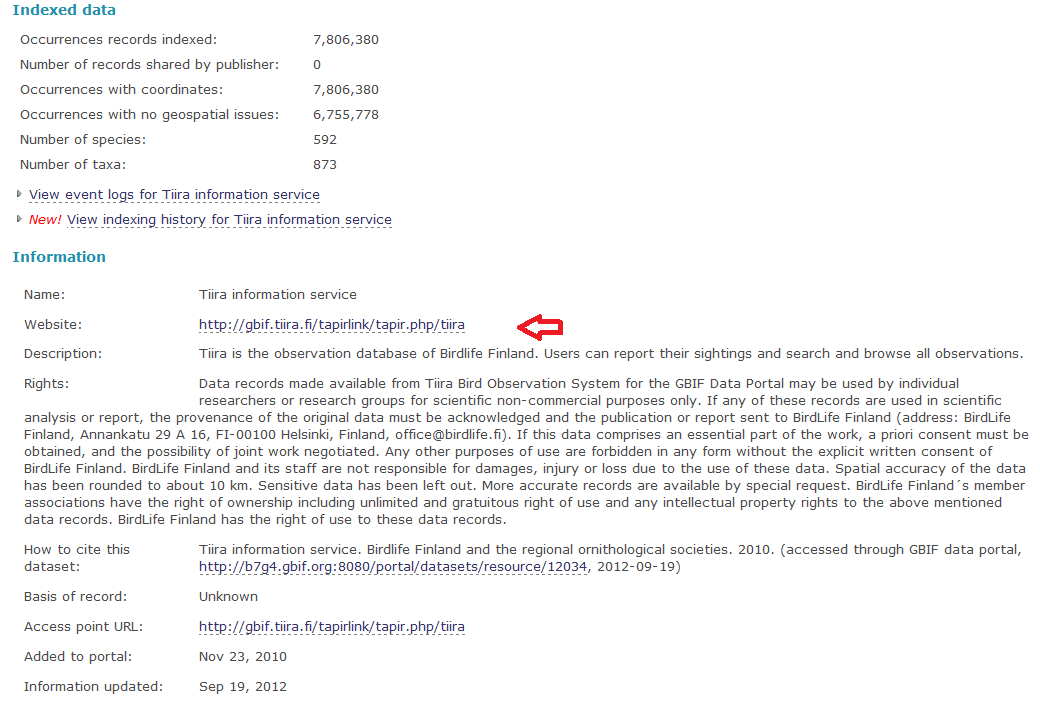
Dataset homepage URL, Tapir: do not use access point url
11925
Reporter: ahahn
Assignee: lfrancke
Type: Bug
Summary: Dataset homepage URL, Tapir: do not use access point url
Priority: Major
Resolution: Invalid
Status: Closed
Created: 2012-09-19 15:28:08.5
Updated: 2013-12-16 17:50:53.781
Resolved: 2013-12-11 14:45:48.553
Description: On a registry page like http://gbrds.gbif.org/browse/agent?uuid=be2af664-2990-4153-99b5-d92bbd8cdb0e (Tiira Information Service dataset), the website URL displayed is the same as the access point URL. It should instead be the URL supplied e.g. under http://www.birdlife.fi/ (TAPIR) for the related entity, see http://gbif.tiira.fi/tapirlink/tapir.php/tiira. This used to be the case in the previous metadata updating workflow (see attached "Tiira_August2012.png)
If several such URLs should exist, it is probably safe to just use the first one, or use the one associated with related entities in a fixed order: if "owner" exists, use that URL, otherwise look at other related entities with related-information values]]>
Author: fmendez@gbif.org
Comment: After thinking a bit about this issue my opinion is that datasets in the registry should be closest as possible to the dataset reported by the endpoint. The TAPIR response doesn't have an url field that points to a human-readable document; so if we can't map that field my suggestion is that we should keep it blank and in the current portal remove the link or explicitly use the data provider url. I know that this is small detail to create a big discussion but my general opinion is that datasets info in general should be the information reported by the endpoint with minimum manipulation.
Created: 2012-09-20 09:54:05.361
Updated: 2012-09-20 09:54:05.361
Author: ahahn@gbif.org
Created: 2012-09-20 10:36:00.42
Updated: 2012-09-20 10:36:00.42
I do not want to inflate that too much either. The main concern is that the information (mostly website URL and logo URL) still needs to be available somewhere for display, as this type of information is important to a number of publishers, so we cannot completely ignore it.
According to the TAPIR specification (http://www.tdwg.org/dav/subgroups/tapir/1.0/docs/tdwg_tapir_specification_2010-05-05.htm - 5.1.2. Metadata Response ff.), it is not possible to transmit a dataset URL, only one for (mostly "data supplier" or "technical host"). As a supplier or host organisation can and often will have several services registered, we are so far not evaluating information contained in the "related entity" blocks at the organisation level, as contradictory information is possible between services. If it is not used at the dataset level, either, it means that the "related entity" information is ignored.
I would argue that we have to add the contact information (only available in ) in any case. There is no other way for a publisher to map those contacts, and we cannot do without them. But then a dataset or publisher logo, as well as website URL, are not fundamentally different. While I agree in principle that we should stay logical in the separation of dataset vs organisation information, we need to keep this kind of information visible somewhere, as both website URL and logo are something that is important to publishers.
Possible options I see:
- TAPIR schema change (unrealistic)
- store information with organisation type agent; display for datasets only with proper reference ("data owner website URL: ....". In this case, we need to resolve potentially conflicting / duplicated information from different services for display at the organisation level, and maintain some reference to the service of origin so that visualisation on the dataset level is possible
- be less strict and assume that for 1:1 type protocols, the information is still relevant enough at dataset level to handle it as part of the dataset information. This is the policy we had so far.
- other?
Author: mdoering@gbif.org
Created: 2012-09-20 16:09:31.934
Updated: 2012-09-20 16:10:00.179
Yes, I dont think we can derive a homepage or logo url for the dataset from a tapir metadata response. That should be kept NULL.
It provides title, description, subject (=public tags), bibliographicCitation (=citation) and rights for the dataset.
The information behind related entities is as it says information about related entities, not the dataset.
Those related entities can be the owning or hosting organization, the funding body or any other entity. From what I know its mostly about organizations and the role tells us what it is. BUT there is no controlled vocabulary, so interpretation needs to be done. And Im not sure if we even want to update any of our organization data with this metadata. So it might be best to ignore it at least for now.
PS: Would be nice to get a list of all different roles that are used in our network so we have an overview.
Author: fmendez@gbif.org
Comment: this is an old metadasync discussion...just want to validate with you that we can't do much about this issue.
Created: 2013-05-14 09:40:03.368
Updated: 2013-05-14 09:40:03.368
Author: kbraak@gbif.org
Created: 2013-12-11 14:45:48.577
Updated: 2013-12-11 14:45:48.577
As [~fmendez@gbif.org] said in his last comment, this issue relates to an older version of the metadata synchronizer.
Please open a new issue if encountering the same issue in the new metadata synchronizer. Thanks